Artificial Intelligence (AI) applications require massive computational power to handle complex mathematical operations like matrix multiplications, deep learning model training, and inference. Over the last decade, three major hardware architectures have become central to AI workloads: Field-Programmable Gate Arrays (FPGAs), Graphics Processing Units (GPUs), and Tensor Processing Units (TPUs). Each of these platforms offers distinct advantages and trade-offs in terms of speed, flexibility, power efficiency, and cost. In this article, we will dive deep into FPGA vs GPU vs TPU, analyze their architectures, compare their performance for different AI tasks, and help you decide the best hardware for your AI applications.
Table of Contents
1. What is an FPGA?
2. What is a GPU?
3. What is a TPU?
4. Architectural Differences
5. Performance Comparison
6. Cost & Power Efficiency
7. Best Use Cases for FPGA, GPU, and TPU
8. FPGA vs GPU vs TPU: Feature Comparison Table
9. Which One Should You Choose?
10. Future Trends in AI Hardware
What is an FPGA?
Field-Programmable Gate Arrays (FPGAs) are reconfigurable integrated circuits. Unlike fixed-function chips, FPGAs can be programmed after manufacturing, which makes them highly versatile for custom hardware acceleration.
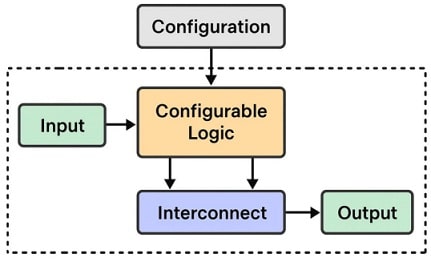
FPGA Structure
Key Features:
- Reconfigurable Architecture: Users can design custom circuits.
- Parallel Processing: Handles multiple tasks simultaneously.
- Low Latency: Ideal for real-time inference.
- Applications: Edge AI, autonomous systems, robotics, signal processing.
What is a GPU?
Graphics Processing Units (GPUs) were originally developed for rendering graphics but have evolved into powerful parallel processors for AI and machine learning.
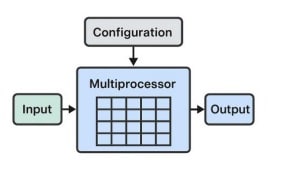
GPU Structure
Key Features:
- Thousands of cores for parallel computations.
- Optimized for matrix operations (critical for deep learning).
- Supported by popular frameworks like TensorFlow, PyTorch, and CUDA.
Applications: Training large neural networks, image recognition, and video analytics.
What is a TPU?
Tensor Processing Units (TPUs) are Application-Specific Integrated Circuits (ASICs) developed by Google specifically for accelerating AI workloads.
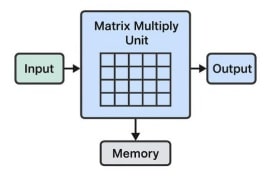
TPU Structure
Key Features:
- Optimized for TensorFlow operations.
- Extremely high throughput for matrix multiplications.
- Cloud-based availability (Google Cloud TPU).
Applications: Large-scale AI inference, Google AI services.
FPGA vs GPU vs TPU Architectural Differences
|
Feature |
FPGA | GPU |
TPU |
|
Type |
Reconfigurable |
General-purpose parallel |
AI-specific ASIC |
|
Latency |
Very Low | Medium | Low |
|
Flexibility |
High | Medium |
Low |
| Programming | VHDL/Verilog | CUDA, OpenCL |
TensorFlow API |
FPGA vs GPU vs TPU Performance Comparison
- FPGAs excel in low-latency, real-time inference tasks.
- GPUs dominate in training large neural networks.
- TPUs are unbeatable in TensorFlow-based deep learning tasks.
|
Metric |
FPGA | GPU |
TPU |
|
Training |
Slow | Fast | Very Fast |
|
Inference |
Fast | Fast |
Fast |
| Power Usage | Low | High |
Medium |
Cost & Power Efficiency
- FPGAs: Lower operational cost, but higher initial development effort.
- GPUs: Widely available, but consume significant power.
- TPUs: Available via Google Cloud; subscription-based pricing.
Best Use Cases
- FPGAs: Autonomous vehicles, IoT edge devices, industrial AI.
- GPUs: Training AI models, video analytics, and computer vision.
- TPUs: NLP, recommendation systems, large-scale cloud AI.
FPGA vs GPU vs TPU : Feature Comparison Table
|
Feature |
FPGA | GPU |
TPU |
|
Flexibility |
High | Medium | Low |
|
Power Eff. |
High | Low |
Medium |
| Ease of Use | Low | High |
High |
Which One Should You Choose?
- If you require flexibility and real-time inference, consider using an FPGA.
- If you need high-speed training and use frameworks like TensorFlow or PyTorch, go with a GPU.
- If you rely on TensorFlow and want cloud-based scalability, TPU is the best.
Future Trends in AI Hardware
- FPGAs are gaining popularity in edge AI.
- GPUs continue to evolve with AI-specific cores.
- TPUs will dominate large-scale, cloud-based AI deployments.